Nowadays, social networks play significantly important roles in everyday life. People produce various sorts of content and consume huge amounts of events at the same time. Actually, it has already weaved into the fabric of everyday life seamlessly. With the prevalence of Twitter, Sina Weibo, Facebook etc., they pose challenges to the traditional media companies and institutes because they react fast and the topic have been propagated through underlying dynamics in real time. There are many interesting research questions raised. Detecting online communities from a given small group of people could help us to understand who will involve in a specific group [1][2]. Topical link or social link prediction and recommendation would facilitate the process of searching related topics or users [3][4]. Meanwhile, emerging hot topics attract more eyeballs and it is pretty important to rank emerging topics and predict the trend [5][6]. Rather than identifying the specific topics, how to explain the information propagation over dynamic networks and figure out the key paths and spreaders still pose challenges [7][8]. Generally speaking, there are more topics to explore rather than listed above. But in this proposal, the points should be focused on the understanding of information propagation over particular topic set. Capturing related data, discovering underlying patterns and visualization should facilitate the journey to unknown world.
A framework should be established to demonstrate the idea. There are five parts to construct a coherent and reasonable project, including data crawling, pre-processing, model mapping and semantic affiliation, pattern mining and visualization [9].
There should be sufficient data so that the distribution of the topic can be represented by the sample from data crawling.
In the process of pre-processing, dirty data should be cleaned and missing value should be given a proper value or the sample with missing value should be discarded.
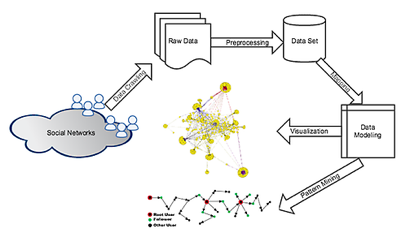
Framework of Social Networks Mining and Visualization
An appropriate model with sufficient enough semantic information support to describe the topic.
As we discussed in literature review, traditional pattern mining methods AGM [10][11], FSG [12], GSPAN [13] and FFSM [14] might be costly to deal with large sub-graph patterns. Both SPIN [15] and MARGINI [16] are introduced to mine maximum frequent subgraphs. But they are still costly in the context of large subgraphs mining. ORIGAMI [16] is introduced to extract a representative set subgraphs. LEAP [17] aims to find most significant patterns directly. GREW [18] is designed to overcome the limitations of existing complete or heuristic frequent subgraphs discovery algorithm. One of the most recent work is SpiderMine [19] ,which is designed to find the top-K largest patterns with a high probability. Unfortunately, ORIGAMI, LEAP, GREW, SpiderMine can’t not process large graphs with constrains. GPRUNE [20] discusses pruning in both pattern space and data space, which is possible to improve the performance of large pattern discovery with constrains. SKINNYMINE [21], proposed by Zhu etc. , gains insights of the properties of constraints of long backbone with short twigs. In the context of social network service, constrains should be considered and GPRUNE [20] and SKINNYMINE [21] can be treated as baseline methods in the study. The challenge of topic propagation is to identify specific constrains and mine the most significant sub graphs effectively.
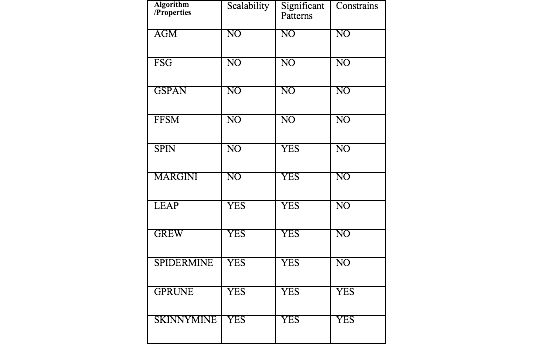
Comparison of Graph Mining Methods
[1]Kloumann, I., & Kleinberg, J. (2014). Community membership identification from small seed sets. Proceedings of the 20th ACM SIGKDD
[2] Duan, L., Street, W. N., Liu, Y., & Lu, H. (2014). Community detection in graphs through correlation. Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining - KDD ’14, 1376–1385.
[3] Barbieri, N., Bonchi, F., & Manco, G. (2014). Who to Follow and Why:Link Prediction with Explanations. Sigkdd.
[4] Zhang, J., Yu, P. S., & Zhou, Z.-H. (2014). Meta-path based Multi-Network Collective Link Prediction Categories and Subject Descriptors. Kdd.
[5] Schubert, E., Weiler, M., & Kriegel, H. (2014). SigniTrend?: Scalable Detection of Emerging Topics in Textual Streams by Hashed Significance Thresholds, 871–880.
[6] Buntine, Wray L., and Swapnil Mishra. "Experiments with non-parametric topic models." Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014.
[7] Pasumarthi, Satya RK, Varun R. Embar, and Indrajit Bhattacharya. "A Bayesian Framework for Estimating Properties of Network Diffusions."
[8] Khalil, Elias Boutros, Bistra Dilkina, and Le Song. "Scalable diffusion-aware optimization of network topology." Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014.
[9] Ch'ng, Eugene. "The Value of Using Big Data Technologies in Computational Social Science." arXiv preprint arXiv:1408.3170 (2014).
[10] Inokuchi, Akihiro, Takashi Washio, and Hiroshi Motoda. "An apriori-based algorithm for mining frequent substructures from graph data." Principles of Data Mining and Knowledge Discovery. Springer Berlin Heidelberg, 2000. 13-23.
[11] Inokuchi, Akihiro, Takashi Washio, and Hiroshi Motoda. "Complete mining of frequent patterns from graphs: Mining graph data." Machine Learning 50.3 (2003): 321-354.
[12] Deshpande, Mukund, et al. "Frequent substructure-based approaches for classifying chemical compounds." Knowledge and Data Engineering, IEEE Transactions on 17.8 (2005): 1036-1050.
[13] Yan, Xifeng, and Jiawei Han. "gspan: Graph-based substructure pattern mining." Data Mining, 2002. ICDM 2003. Proceedings. 2002 IEEE International Conference on. IEEE, 2002.
[14] Huan, Jun, Wei Wang, and Jan Prins. "Efficient mining of frequent subgraphs in the presence of isomorphism." Data Mining, 2003. ICDM 2003. Third IEEE International Conference on. IEEE, 2003.
[15] Huan, Jun, et al. "Spin: mining maximal frequent subgraphs from graph databases." Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2004.
[16] Thomas, Lini T., Satyanarayana R. Valluri, and Kamalakar Karlapalem. "Margin: Maximal frequent subgraph mining." Data Mining, 2006. ICDM'06. Sixth International Conference on. IEEE, 2006.
[17] Yan, Xifeng, et al. "Mining significant graph patterns by leap search."Proceedings of the 2008 ACM SIGMOD international conference on Management of data. ACM, 2008.
[18] Kuramochi, Michihiro, and George Karypis. "Grew-a scalable frequent subgraph discovery algorithm." Data Mining, 2004. ICDM'04. Fourth IEEE International Conference on. IEEE, 2004.
[19] Zhu, Feida, et al. "Mining top-k large structural patterns in a massive network."Proceedings of the VLDB Endowment 4.11 (2011): 807-818.
[20] Zhu, Feida, et al. "gPrune: a constraint pushing framework for graph pattern mining." Advances in Knowledge Discovery and Data Mining. Springer Berlin Heidelberg, 2007. 388-400.
[21] Zhu, Feida, Zequn Zhang, and Qiang Qu. "A direct mining approach to efficient constrained graph pattern discovery." Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. ACM, 2013.
[22] Zhu, Nick Qi. Data Visualization with D3. js Cookbook. Packt Publishing Ltd, 2013.
[23] Bastian, Mathieu, Sebastien Heymann, and Mathieu Jacomy. "Gephi: an open source software for exploring and manipulating networks." ICWSM 8 (2009):361-362
[24] Smith, Marc A., et al. "Analyzing (social media) networks with NodeXL."Proceedings of the fourth international conference on Communities and technologies. ACM, 2009.
This work was carried out at the International Doctoral Innovation Centre (IDIC). The authors acknowledge the financial support from Ningbo Education Bureau, Ningbo Science and Technology Bureau, China's MOST, the University of Nottingham, and Simon See. The work is also partially supported by EPSRC grant no EP/L015463/1.