'Neighbourhoods' are often expressed as the places where events of everyday life occur [1]. They are geographical units to which people connect and identify with. Neighbourhoods are seen as a key element in government agenda, described by Eric Pickles (Secretary of State for Communities and Local Government) as “the building blocks of public services society” [2]. Thus, there is a practical desire to have a set of units that people can relate to – that are statistically large enough to be robust but small enough not to average out actual effects.
However, neighbourhoods do not pre-exist and are human constructions which clearly wouldn't exist without us prior defining them. There is no singular definition of the word 'neighbourhood' and the term has a number of different meanings or formulations. In many countries, including the UK, the subjective nature of neighbourhoods and the difficulties in data collection has meant that there are no official boundaries. The only available national UK neighbourhood data relate to centre points (from such data as Geonames, Yahoo Geoplanet or Open Street Map), however, these do not provide detailed boundary information about the areas.
From a bureaucratic perspective, it is easiest to perceive neighbourhoods as discrete, distinct objects that are nested within current administrative boundaries. However, such administrative boundaries do not necessarily fit with neighbourhood extents even with the same name [3]. This thesis identifies and probabilistically maps the neighbourhood level places that people talk about through the use of passive mining of widespread digital data held on the internet. This is achieved through searches for neighbourhood names within postal addresses held on the internet (for example "21 melbury road * nottingham NG5 4PG" – where the * may possibly contain some 'neighbourhood' descriptor). Although such neighbourhood names are not required for postal delivery, they are often included by users. Fuzzy membership for Soho is shown in Figure One as an example.
The work also classifies the URL data source and webpage content into three groups (estate agents, business directory information and other sources (including user content)) in order to demonstrate the different views of neighbourhood geography that may be perceived.
This body of work has the potential to revise the way in which we map our urban areas. Wilson [4] argues that the geography of neighbourhoods provide a framework within which to observe and analyse social problems within society. Thus, they become units of analysis that are relevant to everyday life and more interpretable for the general public. Imagine data delivery systems that could provide information such as the 2011 Census for the units of analysis that we actually use and associate with (neighbourhood names) as opposed to current administrative boundaries.
Using such neighbourhood bounded data, analysis could be undertaken within a diverse range of applications including neighbourhood planning, Police intelligence, health effects, and social housing preference for tenants. The work also contributes to semantic interoperability concerning vernacular neighbourhoods.
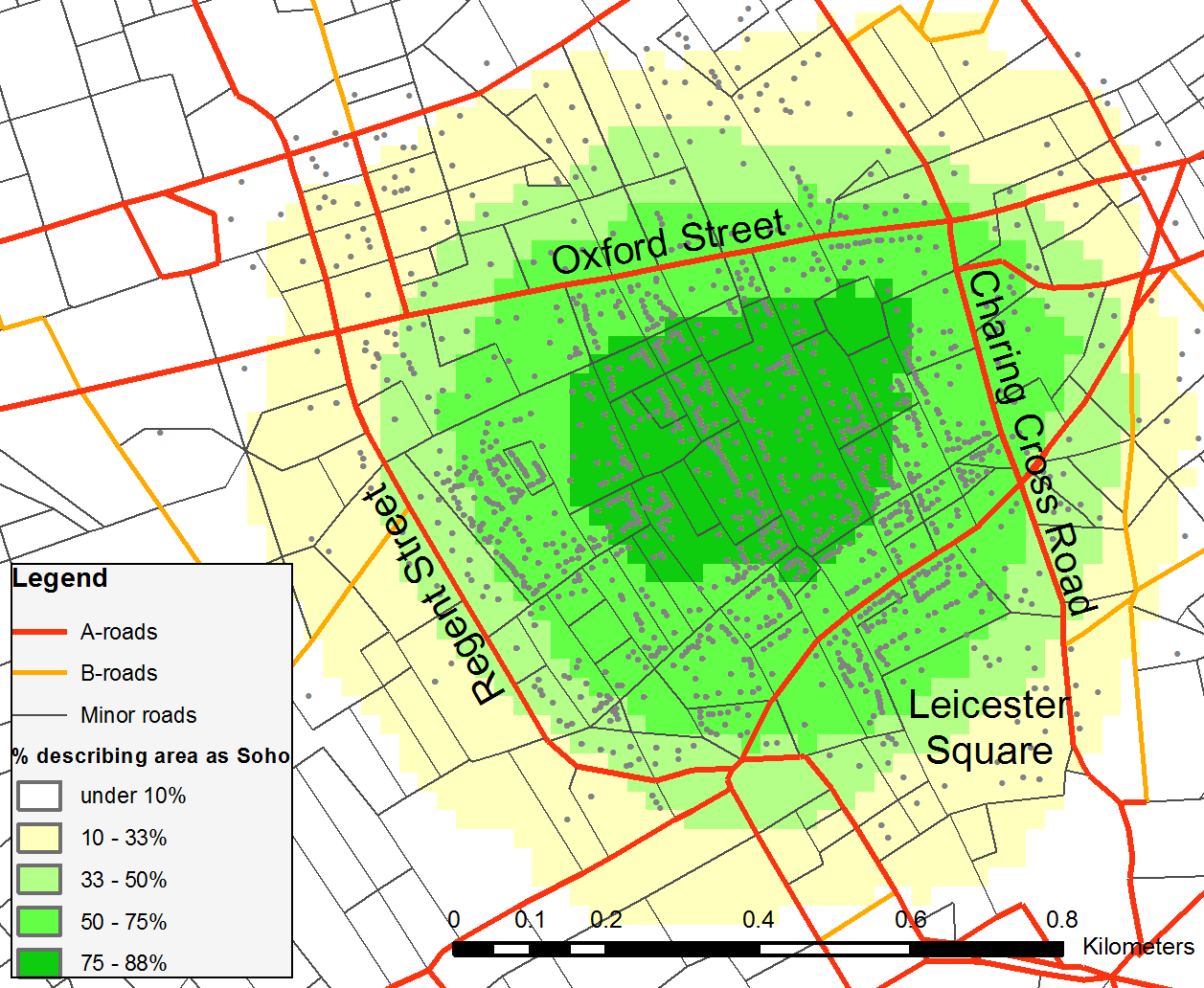
Map of Soho, London based on structured neighbourhood address extraction
‘Contains Ordnance Survey data © Crown copyright and database right 2014’.
This author is supported by the Horizon Centre for Doctoral Training at the University of Nottingham (RCUK Grant No. EP/G037574/1) and by the RCUK’s Horizon Digital Economy Research Institute (RCUK Grant No. EP/G065802/1)