Who am I? One’s identity is a puzzling thing, and is something that we only learn about slowly throughout our life. What exactly constitutes one’s identity is perhaps not entirely known, but we do know that part of it is one’s personality. In the past decades, personality has been conceptualized from various theoretical perspectives, and at different levels of breadth or abstraction [1, 2]. Traditionally, people’s personality evaluation require extensive participation from experienced psychologists and an understanding of the individual’s psychological testing records, history, self-reporting, and assessment during interviews [3]. This is often a lengthy procedure, and relevant data or experts may not always be accessible. As a result, there is an increasing demand for shorter and simper personality measurements [4]. Nowadays, the increasing number of video channels from the internet allows us to store a myriad of spontaneous nonverbal cues extracted from our physical appearance [5]. Thus, it is interesting to see if an automatic system can be built, which can incrementally learn non-verbal cues from facial expressions and audio signals, and predict different traits of people’s personalities
The main research question of this project is that how can we use non-verbal information from video and audio to predict personalities only using machine learning-based systems. To be more specific, we want to explore:
In this project, several state-of-the-art machine learning technologies will be utilized, including Deep Learning [6], Cooperative Learning [7], Bi-directional Long Short-Term Memory Neural Networks [8], Probabilistic Graphical Networks et al.. Meanwhile, feature selection methods will be used to select different audio and video features that correlate to each traits of the personality and depression.
The expected contributions of this PhD project can be summarized as following:
Explore the relationship between each trait of the personality and each combination of AUs.
Create an algorithm to predict people’s personalities from facial expressions and speech signals using the state-of-the-art machine learning technologies.
Explore the relationship between the depression and each combination of AUs.
Create an algorithm to diagnose people’s depression from facial expressions and speech signals using the state-of-the-art machine learning technologies.
Collect a video and audio database for further automatic personality prediction research.
[1] O. P. John, S. E. Hampson, and L. R. Goldberg, "The basic level in personality-trait hierarchies: studies of trait use and accessibility in different contexts," Journal of personality and social psychology, vol. 60, p. 348, 1991.
[2] P. S. Macadam and K. A. Dettwyler, Breastfeeding: biocultural perspectives: Transaction Publishers, 1995.
[3] T. Yingthawornsuk, H. K. Keskinpala, D. M. Wilkes, R. G. Shiavi, and R. M. Salomon, "Direct acoustic feature using iterative EM algorithm and spectral energy for classifying suicidal speech," in INTERSPEECH, 2007, pp. 766-769.
[4] B. Rammstedt and O. P. John, "Measuring personality in one minute or less: A 10-item short version of the Big Five Inventory in English and German," Journal of research in Personality, vol. 41, pp. 203-212, 2007.
[5] L. E. Buffardi and W. K. Campbell, "Narcissism and social networking web sites," Personality and social psychology bulletin, vol. 34, pp. 1303-1314, 2008.
[6] S. Jaiswal and M. Valstar, "Deep learning the dynamic appearance and shape of facial action units," in Applications of Computer Vision (WACV), 2016 IEEE Winter Conference on, 2016, pp. 1-8.
[7] Zhang, Zixing, et al. "Cooperative learning and its application to emotion recognition from speech." IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) 23.1 (2015): 115-126.
[8] Graves, Alex, and Jürgen Schmidhuber. "Framewise phoneme classification with bidirectional LSTM and other neural network architectures." Neural Networks 18.5 (2005): 602-610.
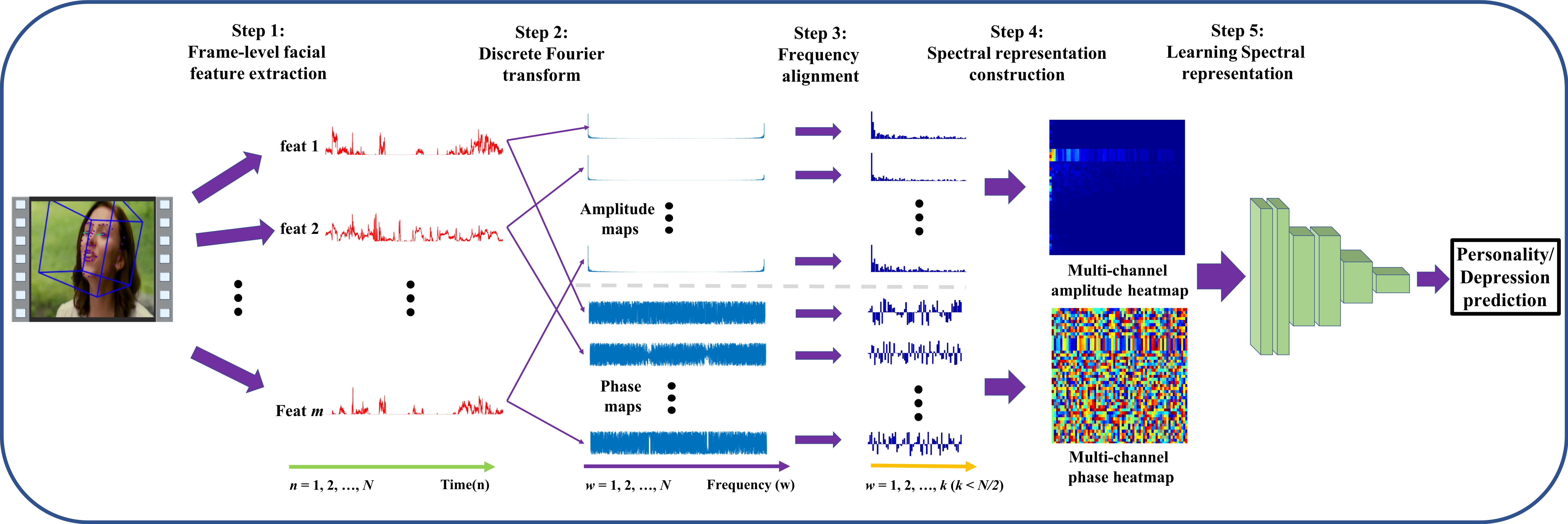
Pipeline of spectral representation-based automatic depression analysis sytem
S. Song, S. Jaiswal, L. Shen and M. Valstar, “Spectral Representation of Behaviour Primitives for Depression Analysis,” in IEEE Transactions on Affective Computing(2020).
S.Song,E. Sánchez, L.Shen, and M. Valstar,“Self-supervised Learning of Dynamic Representations for Static Images,”ICPR2020
S. Jaiswal, S. Song and M. Valstar, “Automatic prediction of Depression and Anxiety from behaviour and personality attributes,” ACII2019
S. Song, E. Sánchez-Lozano, M. K. Tellamekala, L. Shen, A. Johnston and M. Valstar, “Dynamic Facial Models for Video-Based Dimensional Affect Estimation,”ICCVW2019
S. Song, L. Shen and M. Valstar, “Human Behaviour-Based Automatic Depression Analysis Using Hand-Crafted Statistics and Deep Learned Spectral Features,” FG 2018
S. Song, S. Zhang, B. Schuller, L. Shen and M. Valstar, “Noise Invariant Frame Selection: A Simple Method to Address the Background Noise Problem for Text-independent Speaker Verification,” IJCNN 2018
J. Egede*, S. Song*, T. Olugbade*, C. Wang*, A. Williams, H. Meng, M. Aung, N. Lane, M. Valstar and N. Bianchi-Berthouze. “Emopain challenge 2020: Multimodal pain evaluation from facial and bodily expressions.” with FG 2020,
F. Ringeval, B. Schuller, M. Valstar, N. Cummins, R. Cowie, L. Tavabi, M. Schmitt, S. Alisamir, S. Amiriparian, E. Messner, S. Song, S. Liu, Z. Zhao, A. Mallol-Ragolta, Z. Ren, M. Soleymani, and M. Pantic, “AVEC 2019 Workshop and Challenge: State-of-Mind, Detecting Depression with AI, and Cross-Cultural Affect Recognition”. with ACM MM 2019
This author is supported by the Horizon Centre for Doctoral Training at the University of Nottingham (RCUK Grant No. EP/L015463/1) and Nottingham Biomedical Research Centre (BRC).